The following article is an guest blog post from an external researcher (i.e. the author is not a Project Zero or Google researcher).
This post is about a Chrome OS exploit I reported to Chrome VRP in September. The Project Zero folks were nice to let me do a guest post about it, so here goes. The report includes a detailed writeup, so this post will have less detail.
1 byte overflow in a DNS library
In April I found a TCP port listening on localhost in Chrome OS. It was an HTTP proxy built into shill, the Chrome OS network manager. The proxy has now been removed as part of a fix, but its source can still be seen from an old revision: shill/http_proxy.cc. The code is simple and doesn’t seem to contain any obvious exploitable bugs, although it is very liberal in what it accepts as incoming HTTP. It calls into the c-ares library for resolving DNS. There was a possible one byte overflow in c-ares while building the DNS packet. Here is the vulnerable code, stripped heavily from its original to make the bug more visible:

It parses dot-separated labels and writes them into a buffer allocated by malloc(). Each label is prefixed by a length byte and separating dots are omitted. The buffer length calculation is essentially just a strlen(). A dot that follows a label accounts for the length byte. The last label may or may not end with a dot. If it doesn’t, then the buffer length is incremented in the first black box to account for the length byte of the last label.
Dots may be escaped though and an escaped dot is part of a label instead of being a separator. If the last label ends with “\.”, an escaped dot, then the first black box wrongly concludes that the length byte of the last label has already been accounted for. The buffer remains short by one byte and the least significant byte of dnsclass overflows. The value of dnsclass is most commonly a constant 1.
Exploit from JavaScript?
Shill runs as root. A direct exploit from JavaScript would accomplish in a single step what might otherwise take three: renderer code execution -> browser code execution -> privesc to root. This means less work and fewer points of failure. It’s convenient that shill and chrome are separate processes, so if the exploit fails and crashes shill, it doesn’t bring down chrome and shill is restarted automatically. The direct exploit turned out to be possible, but with difficulties.
There doesn’t seem to be an obvious way to get chrome to place “\.” at the end of a Host header using HTTP. So instead the exploit uses the TURN protocol with WebRTC. It encodes what looks like HTTP into the username field of TURN. TURN is a binary protocol and it can only be used because HTTP parsing by the proxy is lax.
Also, shill is listening on a random port. The exploit uses TURN again, to scan the localhost ports. It measures connection time to determine if a port was open. The scan also runs into a surprising behavior explained nicely in here. If the source and destination TCP ports of a localhost connection attempt happen to match, then the kernel connects the socket to itself. Anything sent on a socket is received on the same socket. This causes false positives, so the scan must retry until a single port remains.
A more difficult issue is that there aren’t any decent memory grooming primitives. The proxy allocates the headers into a vector of strings. It applies minimal processing to the Via and Host headers, forwards the headers to another server and frees the them. It accepts a single client at a time. The number of headers is limited to <= 0x7f, header size is <= 0x800 bytes and TURN packet is <= 0x8000 bytes. The rough plan is to do rooming over 6 connections or stages. The problem is that different stages need to reliably place allocations at the same location. This is difficult because the memory layout changes between connections in ways that are hard to predict. The solution is to create what I call a persistent size 0x820 byte hole.
820 hole
First, it should be mentioned that shill uses dlmalloc, which is a best-fit allocator. malloc() uses the smallest free chunk that can fit the request. free() coalesces any neighboring free chunks.
Let’s look at the picture of grooming at stage 1. This creates a persistent hole of 0x820 bytes:
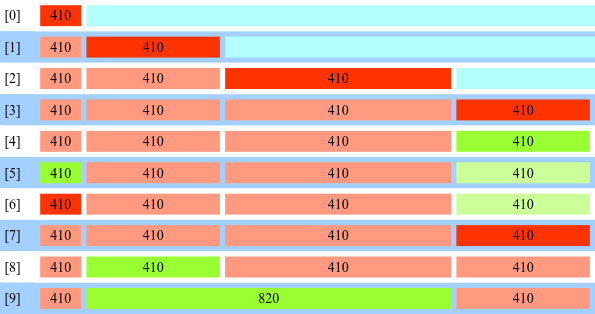
Red means that the chunk is in use chunk and green means free. Cyan is the large top chunk of dlmalloc. The number on each chunk is the chunk size in hex. 0x is omitted. In the rest of this post, I’ll always refer to chunk sizes in hex, omitting 0x. Also, I’ll often refer to chunk sizes as nouns, which is a short way of referring to the chunk with such size. I’ll omit the actual grooming primitives used for these allocations, but for those interested, the Host and Via header processing in here is used.
So the first picture shows how the 820 hole is created. Four chunks of size 410 are allocated from the top chunk in [0-3]. In [5,6], the first 410 is freed and replaced with the backing allocation of the vector of headers. Even though the headers themselves are freed after stage 1 connection closes, the backing allocation of the vector is persistent across connections. The fourth 410 is also freed and the buffer for incoming server data is placed into it. It is also persistent across stages. Then the connection closes, the two 410 headers in the middle are freed and consolidated into 820.
Why is this 820 hole useful? It is persistent because the previous and following 410 are not freed between stages. Each stage can now start with the steps:
- allocate the 820
- eat all free holes up to the top chunk by doing tons of small allocations
- free the 820
Let’s say a stage then allocates a small chunk of 100. dlmalloc uses the smallest free chunk, which is the 820, because smaller ones were allocated. Now let’s say the stage finishes and the 100 is freed. Next stage can use the same algorithm to place a 100 at the same location. This capability allows just enough grooming in stage 2 and 3 to get from one byte overwrite to overlapping chunks.
But things could go wrong. There might be another 820 hole by chance and different stages might allocate a different 820. Or it could happen that the tons of small allocations fail to eat all holes, because the amount of memory allocated per connection is limited. So the exploit attempts to get rid of most of the free chunks before stage 1 by combining different techniques. An interesting one perhaps is that it intentionally crashes shill. The process is restarted automatically and starts with a clean heap layout. It also uses two techniques to allocate lots of memory—more than what’s allowed by the limits mentioned above. I won’t go into details here though.
Overlapping chunks
Stage 2 triggers the memory corruption and stage 3 creates overlapping chunks:

First, a 1e0 chunk is allocated in [10-12] by allocating 640, then 1e0 and then freeing 640. Then the query buffer of ares is allocated into the 110 slot at [13]. This leaves a free 530 in the middle. Now is a good time to take a closer look at the dlmalloc chunk header declared here:

This header is kept in front of each chunk. The 3 least significant bits of the size field are used as flags. Most importantly, lsb = 1 indicates that the previous chunk is in use. So looking at [13], the 530 chunk has size = 531 and 1e0 chunk has prev_size = 530. The prev_size field is only used when the previous chunk is free. Otherwise the previous chunk spans the prev_size field. This means that the size field of 530 immediately follows the query buffer in 110. The single byte that overflows the query buffer overwrites the least significant byte of the size field of 530: 0x31 -> 0x01. So the three flags are not affected. But chunk size is corrupted from 530 to 500 as can be seen from [14].
What’s interesting is that 1e0 doesn’t know anything about this corruption and its prev_size remains 530. Now, [15-17] split the free 500 into free 2e0 and in-use 220. But dlmalloc is already confused at this point. When it tries to update the prev_size of the chunk following 220, it’s off by 30 bytes from 1e0. And 1e0 keeps on believing that prev_size = 530. It also believes that the previous chunk is free even though 220 is in-use. So now in [18], 1e0 is freed. It tries to coalesce with a previous 530 chunk. There is a 2e0, where there used to be 530. dlmalloc is fine with that and creates a large 710 chunk that overlaps the 220.
These kind of overlapping chunks are relatively easy to exploit. They’re good both for breaking ASLR and getting RCE. This technique for going from a single byte overflow to overlapping chunks is not new. Chris Evans demonstrated it here in 2014 as part of an investigation for this Project Zero post. I’m not sure if anyone has demonstrated earlier.
What’s not shown in the picture for simplicity is that [14-15] is the boundary between stage 2 and 3. The memory corruption of stage 2 occurs in DNS code after Via and Host headers are processed, so no further grooming is possible. Stage 3 continues with grooming to get overlapping chunks. But the 110 query buffer is actually freed after stage 2. Stage 3 needs to reallocate a 110 chunk at the same location. The method described above is used.
ASLR
Stage 4 breaks ASLR. It first turns the overlapping 220 into a more convenient 810 chunk:

So it allocates the 820, which overwrites the header of 220 and changes the size to 810. It’s interesting to note that the fd and bk pointers in the header of 220 are also overwritten. The exploit can’t afford to corrupt pointers at this point because it hasn’t broken ASLR. But fd and bk are only used when the chunk is free—they are used for a doubly linked freelist. [21] frees the overwritten chunk and dlmalloc finds it to be of size 810.
Next, two free 2a0 chunks are crafted into the 810:
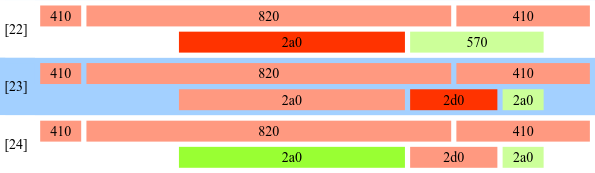
So 2a0 is allocated, 2d0 is allocated and 2a0 is freed. Now, the recently mentioned fd and bk pointers are leaked to break ASLR. The two 2a0 chunks have the same size and are placed into the same freelist. With additional grooming at the beginning of stage 4, the exploit can be certain that the two chunks are the only ones in this freelist. Well, there is also a third element linked in—the freelist head allocated statically from libc. So looking at the first 2a0, its fd and bk point to the other 2a0 and into libc. Also, the first 2a0 overlaps with 820, which contains an HTTP header that is forwarded to an attacker-controlled HTTP proxy. So that leaks two pointers that the proxy server forwards to JavaScript. The two pointers are used to calculate the address of 820 and the base address of libc.
To root
ASLR defeated, stages 5 and 6 get code execution:

The rough idea is to overwrite a BindState which holds callback information—a function pointer and arguments. The function pointer is overwritten to point to system() in libc, the base address of which is known. And the first argument is overwritten to point to a shell command string crafted into the 820 slot, the address of which is also known. BindState chunk size is 40, so now, 810 is resized to 40. First, [25] frees 2d0, which consolidates to 810. For the 810 chunk to be placed into the size 40 freelist, it is removed from its current freelist by allocating it in [27]. 810 size is overwritten to 40 by freeing 820 in [26] and reallocating it with new data in [28]. [29] frees the resized 40 and [30] allocates a BindState into it. BindState now conveniently overlaps with 820. [31-32] reallocates 820 to corrupt the BindState to launch system(). The particular callback used triggers in 30 seconds and system() runs a shell command as root.
Persistence bug
It may sound surprising, but an attacker that has gained root on Chrome OS will lose the privileges after reboot. Chrome OS has verified boot. Bootloader in read-only memory verifies the kernel, which in turn verifies the hash of each disk block that it needs during runtime. This applies to the system partition which contains all the executable binaries, libraries and scripts. So an attacker can’t just set up a script to run at boot. But there is also a stateful partition that can be modified. It is intended for variable stuff like logs, configuration files and caches.
The way this exploit achieves persistence across reboots will sound familiar to anyone who’s read about this exploit by geohot. Both use symlinks, dump_vpd_log and modprobe. The dump_vpd_log script itself was fixed to not follow symlinks, but here is a snippet from /etc/init/ui-collect-machine-info.conf:

/var is a stateful partition so UI_MACHINE_INFO_FILE can be turned into an arbitrary symlink. dump_vpd_log --full --stdout writes /mnt/stateful_partition/unencrypted/cache/vpd/full-v2.txt to stdout. This can be used to create an arbitrary file with arbitrary contents during boot. geohot used dump_vpd_log to write a command into /proc/sys/kernel/modprobe at boot so a following modprobe would execute the command. But there are some extra problems when trying to reuse this approach.
The first issue is that /var/run is a symlink to /run, which is a tmpfs and not persistent. The exploit makes /var/run persistent by relinking it to /var/real_run. Some parts of Chrome OS get confused by that and it is dealt with by using more symlinks. I’ll skip the details here.
modprobe.d config file
So now it’s possible to write into arbitrary files during boot. Another issue is that writing into /proc/sys/kernel/modprobe with dump_vpd_log won’t work in this case, because the following udevadm writes into the same file and its output can’t be controlled. The last write() syscall is what counts when writing into /proc/sys/kernel/modprobe. So instead, the exploit creates /run/modprobe.d, which is is a configuration file for modprobe. Parsing of modprobe.d is lax. Any line starting with "install modulename command..." specifies a command to execute when that module is loaded. Any lines that fail to parse are ignored.
Late modprobe
The final problem is that ui-collect-machine-info.conf runs late during boot, when all modprobing is complete. The created configuration file is not of much use. So the final trick is to find a way to trigger modprobe late during boot. The exploit creates a device file with mknod, which has a major number 173. 173 is unknown to the kernel, which means that when something accesses the device file, then the kernel will attempt to modprobe a handler module named char-major-173-0. Then it is sufficient to turn some commonly accessed file into a symlink to the device file and each access to the file will modprobe. The exploit uses /var/lib/metrics/uma-event.
There is yet one more issue. Stateful partitions are mounted with the nodev flag, which blocks access to device files. So the device has to be moved to /dev during startup. This code in /etc/init/cryptohomed.conf is used for that:

The device is created as /mnt/stateful_partition/home/.shadow/attestation.epb and /mnt/stateful_partition/unencrypted/preserve/attestation.epb is turned into a symlink to /dev/net. This moves the device to /dev/net. /dev/net is used instead of /dev because cryptohomed changes the owner of the target attestation.epb. This would change the owner of the whole /dev directory and cause chrome to crash.
So that completes the Rube Goldberg machine of symlinks. dump_vpd_log creates /run/modprobe.d configuration file with a command to launch as root. cryptohomed moves a device file to /dev/net. Any generated metric accesses the uma-event symlink to the device, which launches modprobe, which launches a command from modprobe.d.
Patches
By now, the issues have been fixed pretty thoroughly. c-ares was patched in Chrome OS and upstream. The HTTP proxy was removed from shill. TURN implementation was hardened to block JavaScript from sending an arbitrary username to a localhost TCP port. And the symlink issues were fixed here, here, here and here.
No comments:
Post a Comment